Precision and Recall
Precision and recall are common ways to evaluate the accuracy of your machine learning or information retrieval model. In other contexts, such as statistics, the measurements around these terms is also known as Type I/Type II errors.
Let’s say you’re working on understanding the relevancy of SnakeSearch, a search engine that looks to find relevant Python documentation for you. Let’s say you want to find documents related to Pandas, as you’re getting started with Pandas, the Python software library, and want some information. You type in “pandas” into SnakeSearch. How good is SnakeSearch’s result set for you?
You get back some set of results.
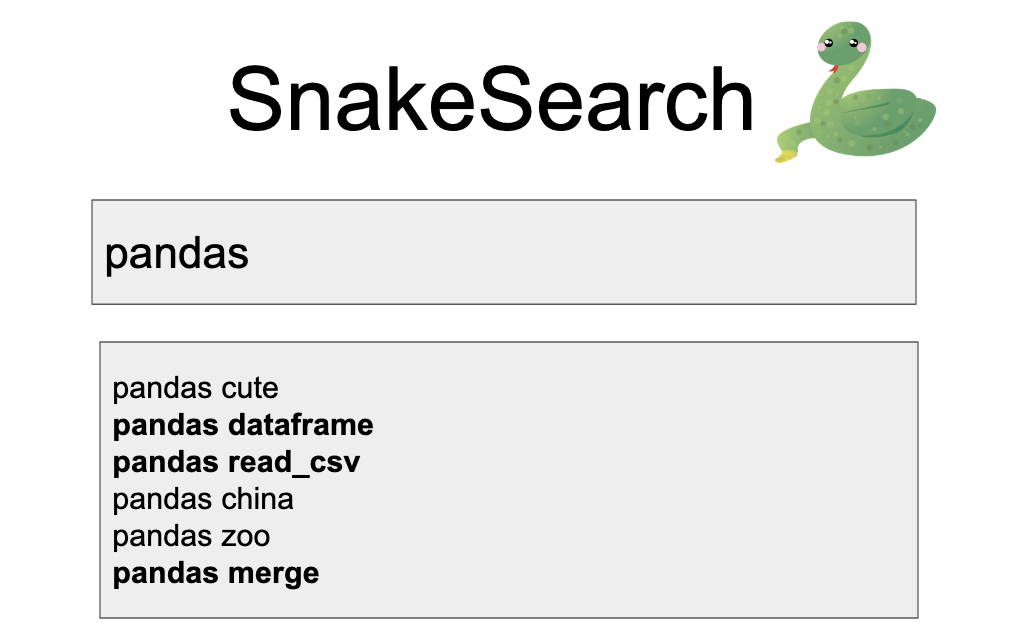
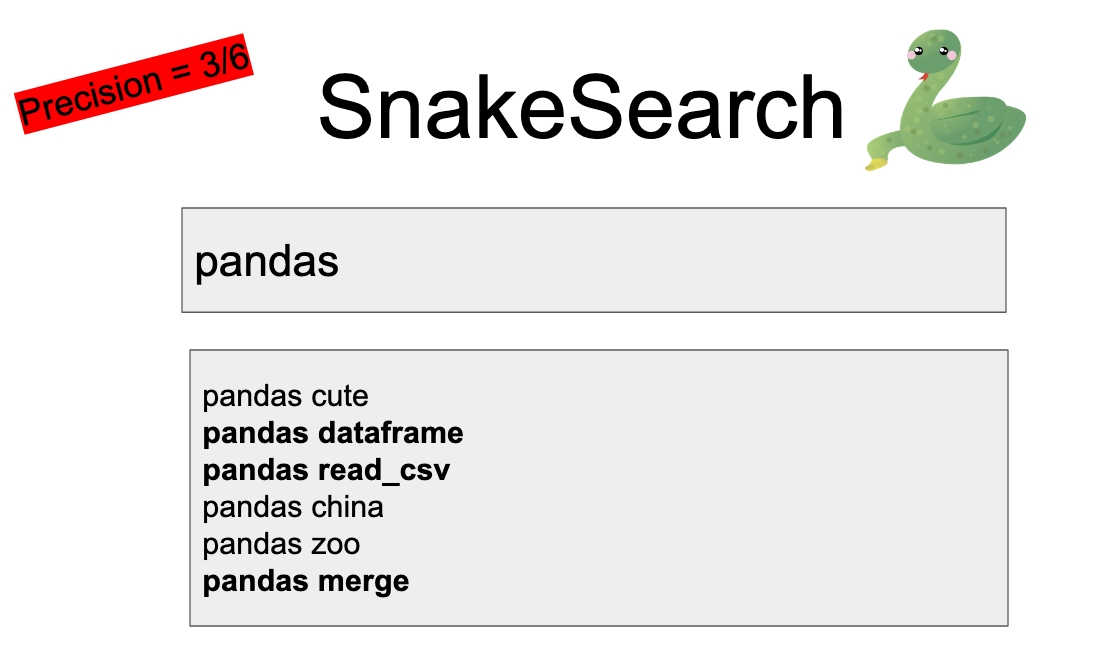
Precision is the percent of returned results that are actually good. So we don’t want the results about real pandas, we want the software library. Precision is 3/6, or 1/2 because 3 of the results are relevant to us.
Recall is what percent of all the possible pandas results out there are returned to you. So let’s say for the case of this example that we have 8 total possible terms. If 3 of those are returned to us, the recall is 3/8.
