
This post is an expansion of this tweet:
If I had to pick a single programming concept where understanding it is like a superpower, it would probably be the hash map (aka in Python, the humble dictionary) because I've seen the pattern come up in almost every kind of data/programming work I've ever done.
— Vicki (@vboykis) July 8, 2020
Hash Aggregate Here #
But data work also has its own unique patterns, and I want to talk about one of these that I think is important for all of us to carry around in our back pockets: the humble hash aggregate. The hash aggregate works like this:
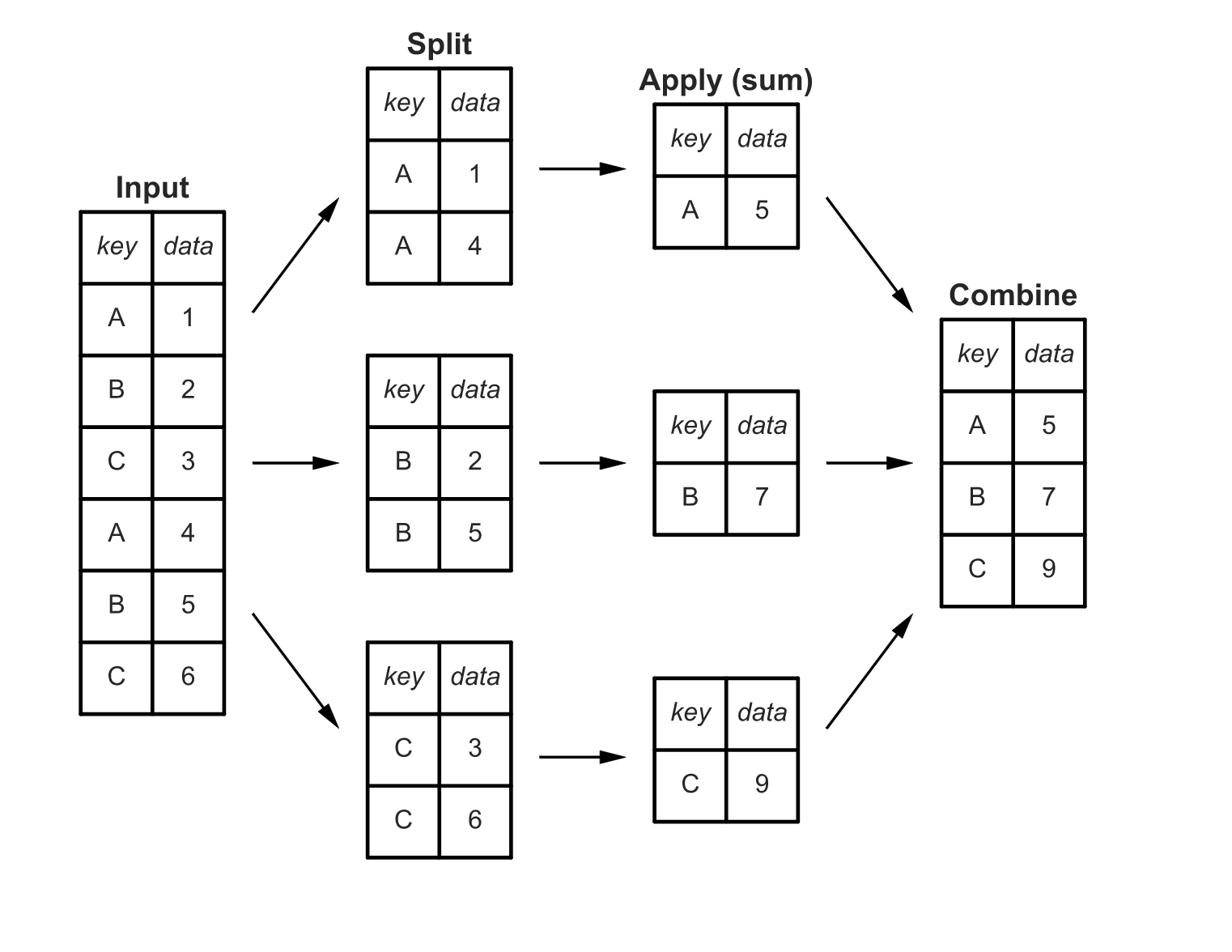
You have a multidimensional array (or, as us plebes say, table) that contains numerous instances of similar labels. What you want to know is the distinct counts of each category. The implemented algorithm splits the matrix by key and sums the values and then returns the reduced matrix that has only unique keys and the sum values to the user.
It’s a very simple and ingenious algorithm, and it shows up over and over and over again. If you’ve ever done a GROUP BY statement in SQL, you’ve used the hash aggregate function. Python’s dictionary operations utilize hash aggregates. And so does Pandas’ split-apply-combine (pictured here from Jake’s great post) And, so does Excel’s Pivot table function. So does sort filename | uniq -c | sort -nr in Unix. So does the map/reduce pattern that started in Hadoop, and has been implemented in-memory in Spark. An inverted index, the foundation for Elasticsearch (and many search and retrieval platforms) is a hash aggregate.
So what? #
If you’ve worked with either development or data for any length of time, it’s almost guaranteed that you’ve come across the need to get unique categories of things and then count the things in those categories. In some cases, you might need to build your own implementation of GROUP BY because it doesn’t work in your language or framework of choice.
My personal opinion is that every data-centric framework that’s been around long enough tends to SQL, so everything will eventually implement hash aggregation.
Once you understand that hash aggregation is a common pattern, it makes sense to observe it at work, learn more about how to optimize it, and generally think about it.
Once we know that this pattern has a name and exists, we have a sense of power over our data work. Confuscius (or whoever attributed the quote to him) once said, “The beginning of wisdom is to call things by their proper name," and either he was once a curious toddler, or an MLE looking to better understand the history and context of his architecture.